
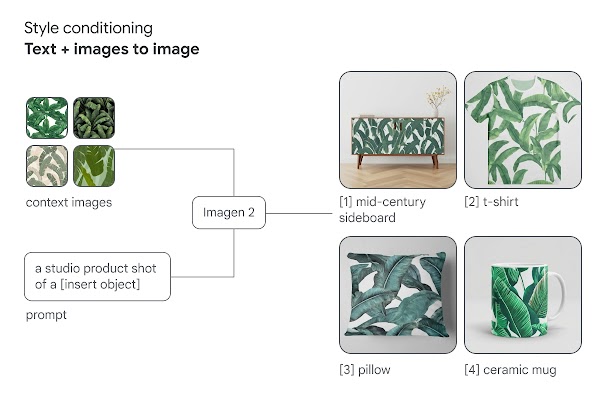
На прошлой неделе корпорация Google объявила о запуске Imagen 2 – улучшенной версии своей генеративной ИИ-модели, которая умеет создавать и редактировать изображения по текстовым подсказкам. На данный момент доступ к продукту открыт только для клиентов Google Cloud, использующих платформу для машинного обучения Vertex AI.
Бета-версия модели была представлена на конференции Google в мае этого года. При создании продукта применялись технологии DeepMind — ИИ-лаборатории корпорации.
По сравнению с Imagen первого поколения, модель научилась генерировать значительно более качественные изображения, а также обзавелась новыми функциями — например, возможностью генерирования логотипов и наложения текстов на изображения. Благодаря этому, инструмент теперь может активно применяться в сфере создания визуальной рекламы. По информации из блога Google, Imagen 2 может генерировать эмблемы, буквенные знаки и абстрактные логотипы, а также накладывать эти элементы на продукты, одежду, визитные карточки и другие виды поверхностей.
Благодаря «новым методам обучения и моделирования» Imagen 2 также научилась распознавать объёмные подсказки с детальными описаниями и давать подробные ответы на вопросы о сгенерированных изображениях. Эти методы также улучшают многоязычное понимание модели, благодаря чему она может трансформировать подсказку на одном языке в выходные данные на другом языке (например, логотип). На данный момент инструмент работает с китайским, хинди, японским, корейским, португальским, английским и испанским языками, а в 2024 году этот список расширится.
Imagen 2 наносит невидимые водяные знаки на сгенерированные ею изображения с помощью технологии SynthID от DeepMind. По информации от корпорации, эти знаки устойчивы к редактированию изображений, включая сжатие, фильтры и настройки цвета, а для их обнаружения требуется специальный инструмент Google, который недоступен широкой аудитории.
Компания не раскрывает информацию о данных, которые использовались для обучения новой модели, что вызывает у критиков ряд вопросов. При разработке Imagen первого поколения сообщалось, что инструмент обучался на общедоступном наборе данных LAION, что также повлекло за собой критику, поскольку в этом наборе находили спорный контент, включая частные медицинские изображения, защищенные авторским правом картины и фейковые изображения знаменитостей интимного характера. В результате тестирований было выявлено, что при определенных запросах модель могла выдавать фотографии реальных людей или авторские работы художников за искусственно сгенерированный контент. Информации о тестировании новой версии модели по этому вопросу на данный момент нет.
Источник: TechCrunch


