Компания Google анонсировала новый экспериментальный инструмент – модель векторизации текста Gemini Embedding. Его добавили в API для разработчиков на базе Gemini.
- Модели векторизации преобразовывают текстовые данные вроде слов и фраз в числовые представления – так называемые эмбеддинги, фиксирующие семантическое значение текста. В частности, эмбеддинги применяются в программах для поиска и классификации документов, позволяя ускорить процесс выполнения задачи и одновременно снизить его стоимость.
- Ранее компания уже выпускала другие модели векторизации, но это первый подобный инструмент, обученный на семействе Gemini. В своем блоге Google сообщила, что модель «унаследовала от Gemini понимание языка и контекстных нюансов», благодаря чему может применяться в широком спектре приложений. При обучении упор делался на общую тематику, за счёт чего инструмент одинаково успешно работает с текстами из сферы финансов, науки, юриспруденции и других областей.
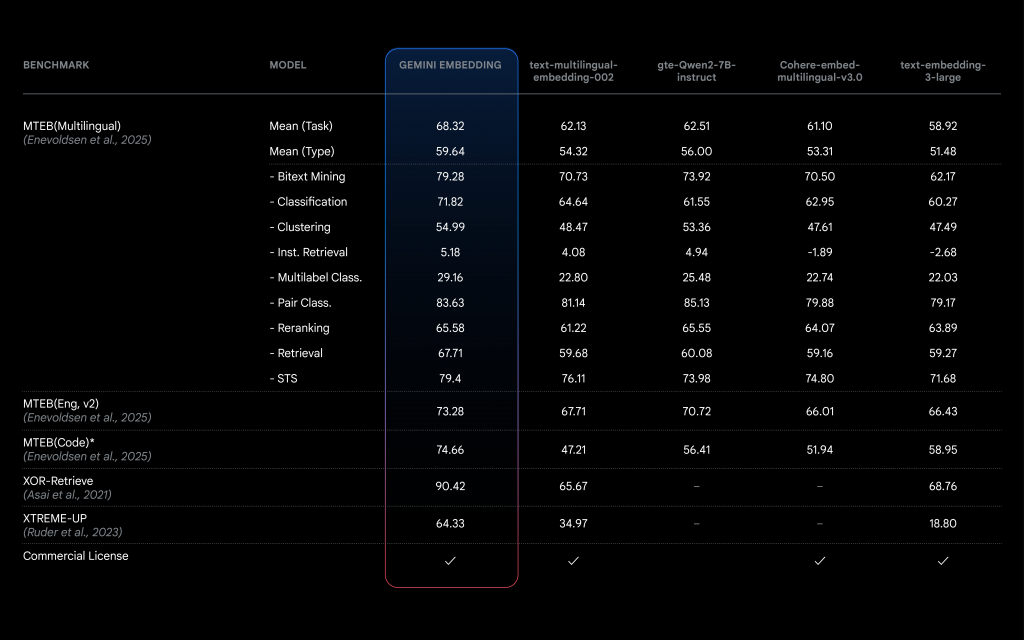
- По утверждению компании, Gemini Embedding показывает более высокие результаты производительности по основным бенчмаркам по сравнению с предыдущей моделью векторизации текста от Google, text-embedding-004. В частности, она может обрабатывать более крупные фрагменты текста или кода и поддерживает в два раза больше языков, а именно – более сотни.
- Сейчас инструмент находится в «экспериментальной фазе», имеет ограничения (её лимит входных токенов ограничен 8 тысячами) и претерпевает изменения в ходе разработки. Как указывается в блоге, релиз полноценной версии модели ожидается через несколько месяцев.
Источник: TechCrunch