

Лаборатория Deep Mind, занимающаяся созданием инструментов на основе искусственного интеллекта, разработала модель машинного обучения Ithaca. Она предназначена для реставрации древнегреческих текстов — инструмент может “угадывать” пропущенные в текстах слова, которые стерлись с источников под воздействием времени, а также определять дату и местоположение создания текста.
Проблема пропущенных частей в древних текстах знакома всем специалистам, работающим с поврежденными древними историческими источниками. Оригинальный древний письменный документ может быть сделан из таких материалов, как камень, глина или папирус — они подвержены повреждениям в результате течения времени, физического ущерба или неосторожного обращения. Также некоторые моменты в текстах может быть сложно расшифровать из-за нестандартного написания или неизученных диалектов.
Пробелы, в которых текст стерт или поврежден, называются в лингвистике лакунами. Лакуной может быть как одна стертая буква, так и отсутствие целых абзацев или даже глав. Расшифровкой и реставрацией таких текстов занимаются специально обученные профессионалы, но в определенных случаях задача правильно угадать пропущенный момент бывает невыполнима. Ithaca разработана как раз для таких случаев.
Инструмент обучен на огромной библиотеке древнегреческих текстов. Он может не только угадать пропущенные слова или фразы, но и с высокой точностью определить возраст текста и место, где он был написан. При этом разработчики подчеркивают, что модель нельзя рассматривать как самостоятельное решение для расшифровки текстов — инструмент призван помочь специалистам, а не заменить их.
Примеры работы Ithaca опубликованы в британском научном журнале Nature: в них инструмент работал с декретами из Афин эпохи Перикла (495-429 г. до н.э.). Специалисты предполагали, что они были написаны примерно в 445 г. до н.э., но на основе текстового анализа Ithaca стало ясно, что реальная дата написания относится к более позднему периоду — примерно 420 г. до н.э., что является существенной разницей для исторических исследований.
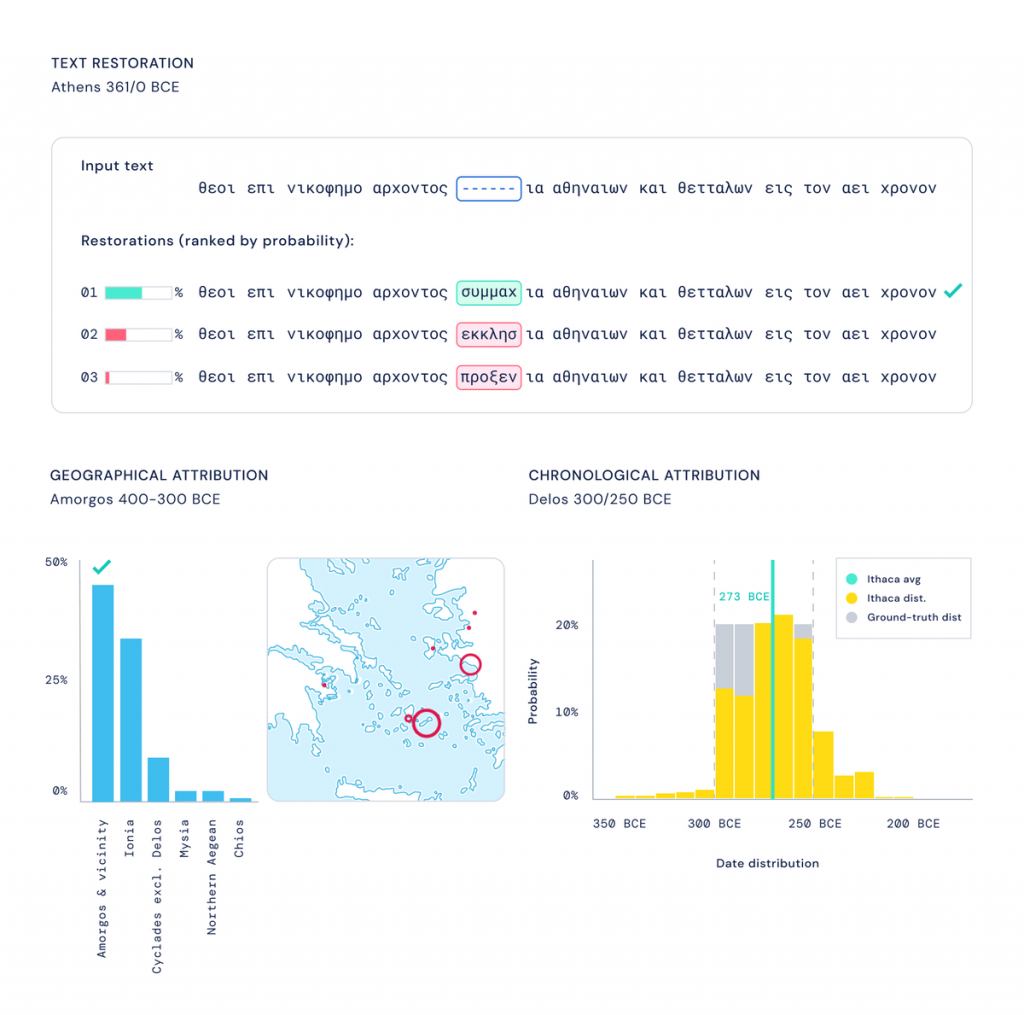
При самостоятельной работе эксперты смогли расшифровать эти декреты примерно с 25% точностью с первого раза (что считается нормальным показателем, так как реставрация текстов — это всегда долгосрочный проект). Однако при использовании инструмента показатель точности довольно быстро достиг 72%. Специалисты смогли ускорить процесс благодаря тому, что Ithaca приходила на помощь в моменты “тупиков” в расшифровке, предлагая отправные точки для продолжения работы.
На сайте Ithaca можно протестировать работу инструмента с помощью самостоятельно найденного небольшого отрывка древнегреческого текста с лакунами (при условии отсутствия не более 10 букв), либо просмотреть один из представленных примеров на платформе. Код для интеграции инструмента доступен на GitHub.
Помимо древнегреческого, команда разработчиков обучает модель и другими языкам: аккадскому, демотическому, ивриту и майя.


